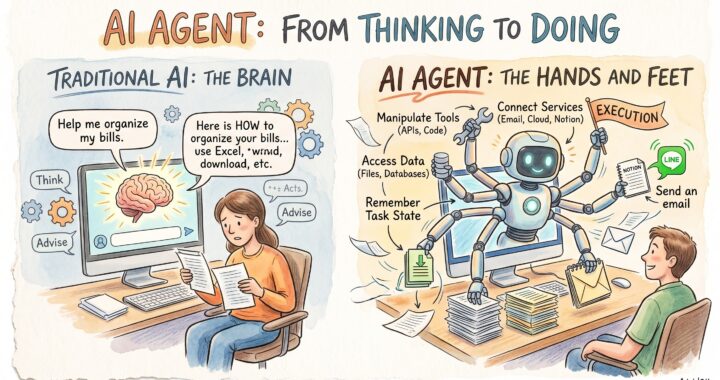
在上一篇文章中,我們探討了 AI Agent(代理)的本質——它不再只是在對話框裡教你「怎麼做」,而是具備了手腳與工具呼叫能力,直接「幫你做」。
但當你興沖沖地部署好 Agent,準備讓它接管日常工作時,很快就會撞上下一道高牆:「對話框的健忘症」。
每一次你開啟新的對話視窗(New Chat),AI 就成了一個對你一無所息的陌生人。你上週與它反覆討論定案的技術架構、你個人偏好的程式碼命名規範、甚至專案的背景脈絡,全部煙消雲散。你必須不厭其煩地重新餵給它「前情提要」,否則它給出的建議就會開始偏離軌道。
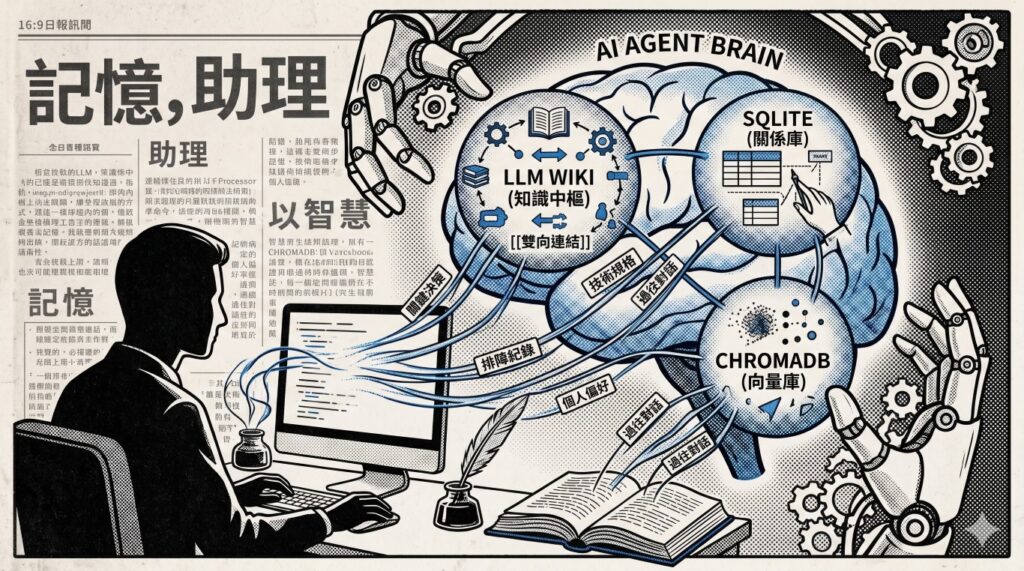
要解決這個問題,我們必須為分身打造一套專屬的長期記憶系統。本篇我們就從實作邏輯出發,聊聊我如何用 LLM Wiki 作為中樞,結合 SQLite 關係庫 與 ChromaDB 向量庫,建立起一套讓 AI 分身不會斷片的雙軌制長期記憶。
一、 脈絡視窗的謊言:大容量不等於好記憶
目前很多大型語言模型都宣稱支援 100 萬甚至 200 萬的 Token 上下文(Context Window)。許多人因此產生一個誤解:「那我把過去幾十萬字的對話歷史和專案文件全部塞給它不就好了?」
但在實際運作中,這會帶來三個致命痛點:
- Lost in the Middle(注意力分散):模型在面對極長上下文時,容易忽略中間段落的關鍵細節,甚至產生邏輯混淆與幻覺。
- Token 費費用的財務黑洞:每次對話你每輸入一個字,AI 都要把過去的幾十萬字重新讀取一遍。如果使用的是付費 API,你的 Token 帳單會以驚人的速度爆炸。
- 資訊污染:垃圾資訊(過時的程式碼嘗試、冗長對話)與黃金決策(最終選用的技術規格)混雜在一起,會直接降低 AI 的輸出智商。
因此,真正合格的 AI 分身,不能只有「大容量硬碟」,更需要一套能夠自動過濾、提煉與分類的長期記憶架構。
二、 記憶的中樞:LLM Wiki (知識合成層)
如果把原始資料(Raw Sources)比喻成未經開採的礦石,LLM Wiki 就是提煉出來的黃金。
在我的個人助理(代號 Antigravity)記憶系統中,我沒有讓 AI 直接去讀取混亂的聊天紀錄或原始檔案,而是引入了 LLM Wiki 作為核心中樞。
簡單來說,LLM Wiki 是一套以人機協同為核心、採用 Markdown 格式書寫的結構化知識庫,它通常被存放在我的本地 Obsidian 筆記庫中,並分成四大維度:
- 實體 (Entities):記錄人物背景、合作夥伴公司,或特定軟硬體產品的技術規格(例如:Vizrt TriCaster, KarismaCG3)。
- 概念 (Concepts):記錄抽象的技術邏輯或工作流(例如:NDI IP 工作流、賽事數據大腦)。
- 綜合 (Synthesis):將多個原始文件融會貫通後的實務調優指引(例如:KCG 控播系統 TVBS 測試與排障紀錄)。
- Blog:存放已發布或撰寫中的個人部落格文章與企劃。
LLM Wiki 最強大的武器,在於它支援 Markdown 的 [[雙向連結]] (Bi-directional Links)。 這讓知識點之間不再孤立,而是像人腦的突觸一樣,縱橫交錯成一張有脈絡的知識網。
三、 三位一體:雙軌制記憶的技術實作
有了 LLM Wiki 作為知識中樞後,我們就可以利用程式碼,圍繞它搭建出「三位一體」的記憶檢索網絡:
graph TD
A["混沌原始資料 raw_sources
會議記錄、對話 Log、PDF"] -->|經過人機協同提煉與合成| B("LLM Wiki 知識中樞
利用雙連結的 MD 筆記")
B --> C["精準關係索引
SQLite 資料庫"]
B --> D["模糊語意檢索
ChromaDB 向量庫"]
C -->| 筆記拓撲與對話決策| E["全局脈絡大卷軸
Notebook Scrolls"]
D -->| 檔案切塊與語意比對| E
E -->| 提供給大腦進行全局推理| F("(AI 分身大腦)")
style B fill:#f9f,stroke:#333,stroke-width:2px
style E fill:#bbf,stroke:#333,stroke-width:1px
1. 精準關係索引庫 (SQLite)
我們使用 SQLite 資料庫(llm_wiki_index.db)來解決「精確定位」的問題。
- 解析雙連結:透過 Python 腳本(
rebuild_index.py)定期掃描 LLM Wiki 筆記,將[[雙向連結]]解析出來並記錄在資料庫的 Link 表中,建立起實體與概念之間的物理關聯。 - 引用出處追蹤 (Citations):明確記錄哪篇 Wiki 頁面是由哪份原始文獻所支持,確保 AI 給出的資訊有據可查。
- 對話決策歸檔 (Agent Memories):每次對話結束前,AI 會自動將最終決策(Decisions)、我的習慣偏好(Preferences)以及關鍵技術細節存入 SQLite,防止下次對話時「忘記約定」。
2. 語意相似度檢索庫 (ChromaDB)
我們使用 ChromaDB 作為向量資料庫,負責「模糊查詢與經驗召回」。
- 腳本會將 LLM Wiki 的 Markdown 文件與原始文獻自動切成碎片(Chunks)並進行向量化。
- 當我提出一個含糊的問題(例如:「之前那個鏡面變藍的問題怎麼解?」),系統會自動進行向量比對,將關聯性最高的排障 Wiki 碎片即時塞給 AI 的上下文。
3. NotebookLM 專用大卷軸 (Notebook Scrolls)
當我們需要 AI 進行全局系統分析或撰寫複雜架構時,碎片的向量檢索會讓 AI「只見樹木不見林」。 因此,我們寫了編譯器(notebook_compiler.py),將 LLM Wiki 中的關聯筆記與 SQLite 中的對話決策,自動融合成數個 NOTEBOOK 大卷軸。你可以直接把這些大卷軸上傳至 NotebookLM,讓 AI 在幾秒鐘內讀完你的完整專案脈絡。
四、 關鍵心法:如何打造「不會退化」的記憶?
在建置這套系統時,我也踩過不少坑,以下是三個我認為最重要的實作心法:
💡 心法 1:智能 Markdown 標題分塊
如果你粗暴地以「每 500 字」切碎文件,AI 檢索到代碼片段時,會因為失去標題,根本不知道這段指令是屬於哪一個專案。 我們在切塊時,必須基於 Markdown 的標題(H1/H2/H3)進行語意切分,並在每個碎片最前方自動補上「麵包屑 context」:
Plaintext
Document: Voxel 專案
Section: 公視台語台採購案
Subsection: 字幕機規格測試
-------------------
(實際的測試數據與代碼...)
這能讓 AI 即使拿到的是碎片記憶,也能瞬間恢復全局背景。
💡 心法 2:對話軌跡壓縮(Conversational Compaction)
在關閉任何長對話之前,先引導 AI 助理執行對話壓縮。讓它總結出本輪對話的關鍵決策、代碼修改軌跡與討論日期,自動寫入 SQLite 長期記憶。下次開啟新視窗時,它讀入這些壓縮後的記錄,就能「一秒接軌」之前的狀態。
💡 心法 3:Obsidian 的人機閉環
將 AI 助理工作區的 Wiki 目錄,直接與你的 Obsidian 本地筆記庫進行雙向同步(利用自動化同步腳本 sync_all)。 你在 Obsidian 裡寫下的專案筆記,會自動成為 AI 的大腦養分;而 AI 幫你整理的決策與排障紀錄,也會同步回你的 Obsidian 供你查閱。至此,你與你的 AI 分身,開始共享同一個知識庫。
結語:記憶,是分身與聊天機器人的分水嶺
一個沒有記憶的 AI,充其量只是個拋棄式的「聊天工具」;而一個擁有長期記憶、與你共享 LLM Wiki 知識庫、記住你每一次決策的分身,才開始真正具備「助理」的靈魂。
這套系統讓我的個人助理 Antigravity 不再需要繁瑣的初始化引導。下一篇,我們將進入實戰的下半場:如何讓具備記憶的分身,透過本地工具呼叫(System Calling)真正幫我們自動化執行工作。